Mẹo về Hướng dẫn dùng panda meaning python Chi Tiết
Bạn đang tìm kiếm từ khóa Hướng dẫn dùng panda meaning python được Cập Nhật vào lúc : 2022-10-31 21:40:10 . Với phương châm chia sẻ Kinh Nghiệm Hướng dẫn trong nội dung bài viết một cách Chi Tiết 2022. Nếu sau khi đọc Post vẫn ko hiểu thì hoàn toàn có thể lại phản hồi ở cuối bài để Admin lý giải và hướng dẫn lại nha.
Thư viện pandas python là gì? Nó hoàn toàn có thể giúp bạn những gì và làm thế nào để sử dụng thư viện pandas này trong lập trình python. Hãy cùng Lập trình không khó đi tìm câu vấn đáp cho những vướng mắc trên trong nội dung bài viết ngày ngày hôm nay. Tôi tin rằng đấy là một nội dung bài viết cực kỳ hữu ích. Nó chắc như đinh sẽn mang lại cho những bạn nhiều kiến thức và kỹ năng có ích và làm chủ được cách sử dụng thư viện này.
Nội dung chính Show
- Thư viện pandas là gì?
- Cài đặt Pandas
- Đọc file csv sử dụng thư viện pandas
- Thao tác với dataframe trong pandas
- Xem thông tin của dataframe
- Truy xuất tài liệu trên dataframe
- Thêm, sửa, xóa trong dataframe
- Hiểu tài liệu trong dataframe
- Tạo mới dataframe
- Tạo mới dataframe từ python dictionary
- Tạo mới dataframe từ những python list
- Một số thao tác khác trên dataframe
- Sắp xếp dataframe
- Nối 2 dataframe
- Xáo trộn những bản ghi trong dataframe
- Lưu dataframe về file csv
- Tài liệu tìm hiểu thêm
Toàn bộ source code hướng dẫn của bài học kinh nghiệm tay nghề bạn hoàn toàn có thể xem
và tải về tại đây.
Thư viện pandas là gì?
Thư viện pandas trong python là một thư viện mã nguồn mở, tương hỗ đắc lực trong thao tác tài liệu. Đây cũng là bộ công cụ phân tích và xử lý tài liệu mạnh mẽ và tự tin của ngôn từ lập trình python. Thư viện này được sử dụng rộng tự do trong cả nghiên cứu và phân tích lẫn tăng trưởng những ứng dụng về khoa học tài liệu. Thư viện này sử dụng một
cấu trúc tài liệu riêng là Dataframe. Pandas phục vụ thật nhiều hiệu suất cao xử lý và thao tác trên cấu trúc tài liệu này. Chính sự linh hoạt và hiệu suất cao đã làm cho pandas được sử dụng rộng tự do.
Tại sao sử dụng thư viện pandas?
- DataFrame đem lại sự linh hoạt và hiệu suất cao trong thao tác tài liệu và lập chỉ mục;
- Là một công cụ được cho phép đọc/ ghi tài liệu giữa bộ nhớ và nhiều định dạng file: csv, text, excel, sql database, hdf5;
- Liên kết tài liệu thông
minh, xử lý được trường hợp tài liệu bị thiếu. Tự động đưa tài liệu lộn xộn về dạng có cấu trúc; - Dễ dàng thay đổi bố cục của tài liệu;
- Tích hợp cơ chế trượt, lập chỉ mục, lấy ra tập con từ tập tài liệu lớn.
- Có thể thêm, xóa những cột tài liệu;
- Tập hợp hoặc thay đổi tài liệu với group by được cho phép bạn thực thi những toán tử trên tập tài liệu;
- Hiệu quả cao trong trộn và phối hợp những tập tài liệu;
- Lập chỉ mục theo những chiều của tài liệu giúp thao tác giữa tài liệu
cao chiều và tài liệu thấp chiều; - Tối ưu về hiệu năng;
- Pandas được sử dụng rộng tự do trong cả học thuật và thương mại. Bao gồm thống kê, thương mại, phân tích, quảng cáo,…
Cài đặt Pandas
Để setup thư viện Pandas, bạn hoàn toàn có thể tuân theo một số trong những cách rất khác nhau theo tài liệu hướng dẫn:
Bây giờ toàn bộ chúng ta sẽ
khởi đầu học cách sử dụng thư viện pandas python. Nhưng trước lúc khởi đầu, hãy import thư viện pandas nhé. Chúng ta sẽ dùng cả thư viện matplotlib nữa.
Nếu bạn chưa chắc như đinh về thư viện matplotlib, hãy tìm hiểu thêm nội dung bài viết này trước nhé.
# Render our plots inline
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import random
Đọc file csv sử dụng thư viện pandas
Bạn hoàn toàn có thể thuận tiện và đơn thuần và giản dị đọc vào một trong những file .csv bằng phương pháp sử dụng hàm read_csv và được trả về 1 dataframe. Mặc định, hàm này
sẽ phân biệt những trường của file csv theo dấu phẩy. Cách đọc rất là đơn thuần và giản dị như sau:
peoples_df = pd.read_csv(‘./people.csv’)
Bạn hoàn toàn có thể in ra n bản ghi thứ nhất của dataframe sử dụng hàm head. trái lại của hàm head là hàm tail
peoples_df.head(5)
Kết quả in ra như sau: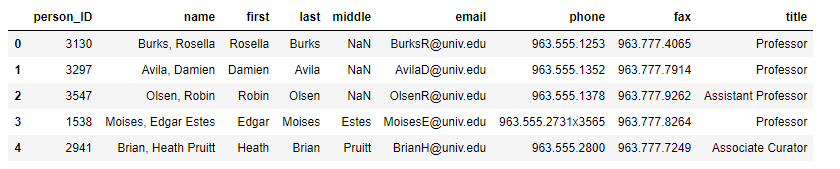
Tuy nhiên, bạn cũng tiếp tục phải lưu ý một vài tham số của hàm read_csv như:
- encoding: chỉ
định encoding của file đọc vào. Mặc định là utf-8. - sep: thay đổi dấu ngăn cách Một trong những cột. Mặc định là dấu phẩy (‘,’)
- header: chỉ định file đọc vào có header(tiêu đề của những cột) hay là không. Mặc định là infer.
- index_col: chỉ định chỉ số cột nào là cột chỉ số(số thứ tự). Mặc định là None.
- n_rows: chỉ định số bản ghi sẽ đọc vào. Mặc định là None – đọc toàn bộ.
Ví dụ:
peoples_df = pd.read_csv(‘./people.csv’, encoding=’utf-8′, header=None, sep=’,’)
peoples_df.head(5)
Khi tôi chỉ định không còn header, dòng
header của toàn bộ chúng ta đang trở thành 1 bản ghi tài liệu: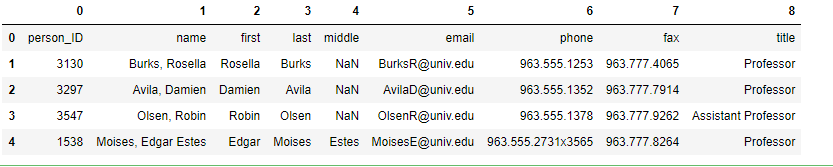
Bạn đọc hoàn toàn có thể xem mô tả khá đầy đủ từng tham số của hàm read_csv của thư viện pandas python tại đây.
Thao tác với dataframe trong pandas
Xem thông tin của dataframe
Bạn hoàn toàn có thể xem thông tin của dataframe vừa đọc vào bằng phương pháp sử dụng hàm .info() hoặc xem kích thước của dataframe này với thuộc tính shape. Cụ thể như sau:
# Xem chiều dài của df, tương tự shape[0]
print(‘Len:’, len(peoples_df))
# Xem thông tin dataframe vừa đọc được
peoples_df.info()
# Xem kích thước của dataframe
print(‘Shape:’, peoples_df.shape)
Và kết quả thu được là:
Len: 40
<class ‘pandas.core.frame.DataFrame’>
RangeIndex: 40 entries, 0 to 39
Data columns (total 11 columns):
person_ID 40 non-null int64
name 40 non-null object
first 40 non-null object
last 40 non-null object
middle 15 non-null object
email 40 non-null object
phone 40 non-null object
fax 40 non-null object
title 40 non-null object
age 40 non-null int64
is_young 40 non-null bool
dtypes: bool(1), int64(2), object(8)
memory usage: 3.2+ KB
Shape: (40, 11)
Truy xuất tài liệu trên dataframe
Lấy 1 cột theo tên cột
Để chỉ định cột muốn lấy, bạn chỉ việc truyền vào tên cột như sau:
peoples_df[‘name’]
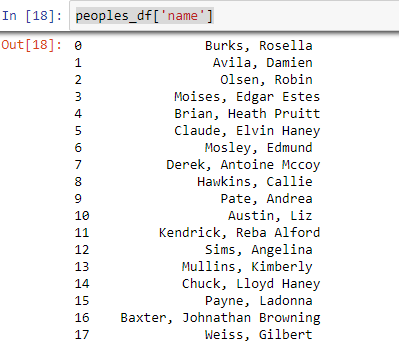
Lấy theo nhiều cột
Thay vì truyền vào 1 string thì hãy truyền vào 1 list những tên cột. Mình thêm .head(5) để chỉ in ra 5 bản ghi thứ nhất cho ngắn, mặc định sẽ lấy hết.
peoples_df[[‘name’, ‘age’]].head(5)
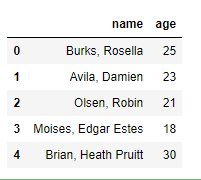
Lấy
bản ghi theo chỉ số
Để lấy một hoặc nhiều bản ghi liên tục trong dataframe, sử dụng cơ chế trượt theo chỉ số in như trên list trong python. Lấy 5 bản ghi thứ nhất:
peoples_df[0:5]
Trong trường hợp này kết quả in như hàm head phía trên. Đều là lấy 5 bản ghi thứ nhất.
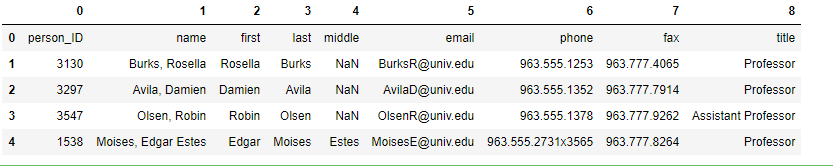
Bạn
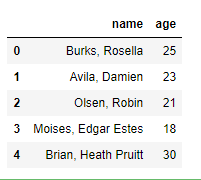
cũng hoàn toàn có thể phối hợp lấy theo hàng và cột mong ước:
peoples_df[[‘name’, ‘age’]][:5]
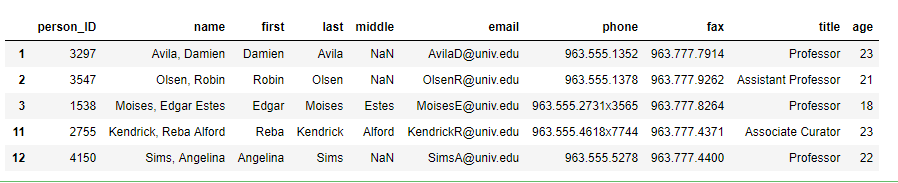
Lấy những bản ghi theo Đk
young_pp = peoples_df[peoples_df[‘age’] < 25]
young_pp[:5]
Một ví dụ
khác: Lấy toàn bộ những bản ghi chứa thông tin của người dân có chức vụ là giáo sư:
professor = peoples_df[peoples_df.title == ‘Professor’]
professor.head(5)

Hoặc 1 ví dụ so sánh chuỗi như sau:
name_compare = peoples_df[‘name’].str.contains(‘Rosella’)
name_compare.head(5)
Kết quả thu được là một dataframe có một cột chưa 2 giá trị True hoặc False
0 True
1 False
2 False
3 False
4 False
Name: name, dtype: bool
Lấy giá trị trả về numpy arrays
Để lấy giá
trị của một cột trả về dưới dạng numpy array trong thư viện pandas python, bạn chỉ việc thêm .values vào sau, ví dụ:
peoples_df[‘name’].values
Output bạn thu được như sau:
array([‘Burks, Rosella ‘, ‘Avila, Damien ‘, ‘Olsen, Robin ‘,
‘Moises, Edgar Estes’, ‘Brian, Heath Pruitt’,
‘Claude, Elvin Haney’, ‘Mosley, Edmund ‘, ‘Derek, Antoine Mccoy’,
‘Hawkins, Callie ‘, ‘Pate, Andrea ‘, ‘Austin, Liz ‘,
‘Kendrick, Reba Alford’, ‘Sims, Angelina ‘, ‘Mullins, Kimberly ‘,
‘Chuck, Lloyd Haney’, ‘Payne, Ladonna ‘,
‘Baxter, Johnathan Browning’, ‘Weiss, Gilbert ‘,
‘Deirdre, Florence Barrera’, ‘Fernando, Toby Calderon’,
‘Garrison, Patrica ‘, ‘Effie, Leila Vinson’, ‘Buckley, Rose ‘,
‘Stanton, Kathie ‘, ‘Banks, Shannon ‘, ‘Barnes, Cleo ‘,
‘Brady, Nellie ‘, ‘Katheryn, Ruben Holt’, ‘Michael, Dianne ‘,
‘Grant, Adam ‘, ‘Head, Kurtis ‘, ‘Berger, Jami ‘,
‘Earline, Jaime Fitzgerald’, ‘Evelyn, Summer Frost’,
‘Quentin, Sam Hyde’, ‘Dunlap, Ann ‘, ‘Shields, Rich Pena’,
‘Page, Winnie ‘, ‘Sparks, Ezra ‘, ‘Kaufman, Elba ‘], dtype=object)
Nếu bạn quan tâm tới numpy array, hãy tìm đọc bài hướng dẫn về numpy
Thêm, sửa, xóa trong dataframe
Thêm cột từ tài liệu mới
Để thêm cột vào một trong những dataframe có sẵn. Trước tiên, bạn nên phải có một list tài liệu
tương ứng với cột mà bạn muốn thêm. Tức là chiều dài của list phải tương ứng với số bản ghi của dataframe bạn muốn thêm.
Ở đây, tôi sẽ sử dụng thư viện random để sinh ngẫu nhiên một list năm sinh và thêm vào dataframe như sau:
df_len = len(peoples_df)
birthday = [random.randrange(1980, 2000, 1) for i in range(df_len)]
peoples_df[‘birthday’] = birthday
peoples_df.tail(5)

Thêm cột nhờ vào tài liệu đã có
Giả sử ở đây mình yêu thích thêm cột is_young có mức giá trị
True nếu tuổi < 25 và False trong trường hợp còn sót lại.
peoples_df[‘is_young’] = peoples_df[‘age’] < 25
peoples_df.head(5)

Khởi tạo cột mới có mức giá trị rỗng
Sử dụng cú pháp đơn thuần và giản dị như dưới đây, bạn sẽ có được một trường mới và toàn bộ những giá trị là None
peoples_df[‘new_column’] = None
Thêm bản ghi trong
dataframe
Về yếu tố thêm bản ghi, toàn bộ chúng ta thường ít khi sử dụng nên tôi sẽ không còn trình diễn. Bạn đọc quan tâm hoàn toàn có thể đọc thêm tại tài liệu này
Sửa giá trị của cột
Để sửa giá trị của một cột, bạn làm tương tự như thêm mới cột. Nhưng khác với thêm ở đoạn là tên thường gọi cột bạn truyền vào đã có trong dataframe. Còn thêm là một trong tên trường mới hoàn toàn chưa
có. Chẳng hạn, bạn muốn thay đổi trường name, bạn chỉ việc làm như sau:
peoples_df[‘name’] = xxx #list những tên mới có chiều dài bằng chiều dài của dataframe
// Hoặc reset trường name về None
peoples_df[‘name’] = None
Xóa cột trong dataframe
Bạn hoàn toàn có thể sử dụng một trong những phương pháp sau:
peoples_df.drop(‘tên cột cần xóa’, axis=1) # Xóa 1 cột
peoples_df.drop([‘cột 1’, ‘cột 2’], axis=1) # Xóa nhiều cột
df.drop(columns=[‘B’, ‘C’]) # Xóa những cột mang tên là B và C
Xóa bản ghi theo chỉ số
peoples_df.drop([0, 1]) # Xóa bản ghi ở chỉ số 1 và 2
Hiểu tài liệu trong dataframe
Thư viện pandas python phục vụ cho bạn một số trong những hàm giúp bạn hiểu về cấu trúc, phân loại của tài liệu. Dưới đấy là phương pháp để bạn mày mò và hiểu tài liệu của tớ.
Tôi đã tương hỗ update trường age vào file people.csv và
tiến hành đọc lại.
peoples_df[‘age’]
0 25
1 23
2 21
3 18
4 30
5 35
.
.
.
38 25
39 25
Name: age, dtype: int64
Sử dụng hàm describe() cho bạn những thống kê cơ bản về tài liệu:
peoples_df.describe()
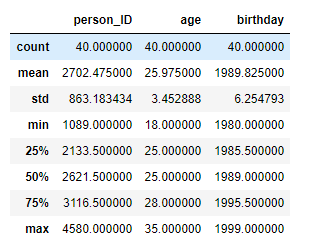
Xem thống kê rõ ràng hơn trên từng cột như sau:
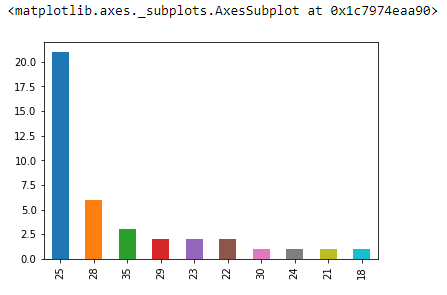
peoples_df[‘age’].value_counts()
25 21
28 6
35 3
29 2
23 2
22 2
30 1
24 1
21 1
18 1
Name: age, dtype: int64
Bạn cũng hoàn toàn có thể vẽ đồ thị xem phân loại giá trị của một trường trong dataframe như sau:
peoples_df[‘age’].value_counts().plot(kind=’bar’)
Tạo mới dataframe
Có một vài phương pháp để tạo ra dataframe trong thư viện pandas python. Bạn hoàn toàn có thể dùng cách mà bạn cho là dễ sử dụng, đôi lúc cũng phải tùy vào từng trường hợp mà nên lựa chọn cách nào nữa.
Tạo mới dataframe từ python dictionary
peoples = ‘name’: [‘Nguyễn Văn Hiếu’, ‘Hiếu Nguyễn Văn’], ‘age’: [28, 28], ‘website’: [‘https://nguyenvanhieu.vn’, None]
df = pd.DataFrame(peoples)
print(df)
Bạn sẽ có được một dataframe như sau:
name age website
0 Nguyễn Văn Hiếu 28 https://nguyenvanhieu.vn
1 Hiếu Nguyễn Văn 28 None
Tạo mới dataframe từ những python list
txts = [‘chỗ này ăn cũng khá ngon’, ‘ngon, nhất định sẽ quay lại’, ‘thái độ phục vụ quá tệ’]
labels = [1, 1, 0]
df = pd.DataFrame()
df[‘txt’] = txts
df[‘label’] = labels
print(df)
Và dataframe
mà bạn sẽ thu được là:
txt label
0 chỗ này ăn cũng rất ngon 1
1 ngon, nhất định sẽ quay trở lại 1
2 thái độ phục vụ quá tệ 0
Lưu ý: những list này phải có cùng kích thước.
Một số thao tác khác trên dataframe
Sắp xếp dataframe
Với thư viện pandas python, bạn hoàn toàn có thể sắp xếp dataframe tăng dần, hay giảm dần theo 1 hoặc nhiều cột chỉ định.
# Sắp xếp df tăng dần theo cột nào đó
df = pd.DataFrame(‘name’: [‘Nam’, ‘Hiếu’, ‘Mai’, ‘Hoa’], ‘age’: [18,18,17,19])
print(‘Before sortn’, df)
df = df.sort_values(‘age’, ascending=True)
print(‘After sortn’, df)
Kết quả thu được như sau:
Before sort
name age
0 Nam 18
1 Hiếu 18
2 Mai 17
3 Hoa 19
After sort
name age
2 Mai 17
0 Nam 18
1 Hiếu 18
3 Hoa 19
Bạn hoàn toàn có thể sắp xếp theo nhiều cột có độ ưu tiên giảm dần, bằng phương pháp truyền vào list tên cột. Ví dụ:
df.sort_values([‘age’, ‘name’], ascending=True)
Nối 2 dataframe
Bạn hoàn toàn có thể nối 2
dataframe thành 1 dataframe mới bằng phương pháp sử dụng hàm append của thư viện pandas.
# Gộp 2 dataframe
df1 = pd.DataFrame(‘name’: [‘Hiếu’], ‘age’: [18], ‘gender’: [‘male’])
df2 = pd.DataFrame(‘name’: [‘Nam’, ‘Mai’, ‘Hoa’], ‘age’: [15,17,19])
df = df1.append(df2, sort=True)
print(df)
Kết quả:
age gender name
0 18 male Hiếu
0 15 NaN Nam
1 17 NaN Mai
2 19 NaN Hoa
Xáo trộn những bản ghi trong dataframe
Trong xử lý tài liệu, bạn chắc như đinh sẽ cần tới việc xáo trộn tài liệu. Rất may, thư viện pandas hoàn toàn có thể giúp toàn bộ chúng ta thao tác đó.
# Xáo trộn những hàng trong df – shuffle dataframe rows
df = pd.DataFrame(‘name’: [‘Hiếu’, ‘Nam’, ‘Mai’, ‘Hoa’], ‘age’: [18,15,17,19])
print(‘Before shufflen’, df)
df = df.sample(frac=1).reset_index(drop=True)
print(‘After shufflen’, df)
Kết quả(Có thể rất khác nhau nhé – xáo trộn mà)
Before shuffle
name age
0 Hiếu 18
1 Nam 15
2 Mai 17
3 Hoa 19
After shuffle
name age
0 Mai 17
1 Nam 15
2 Hiếu 18
3 Hoa 19
Giải thích thêm:
- frac: Chỉ định số bản ghi sẽ trả về ở mỗi lần random. Nếu bằng 1, tức là random ngẫu nhiên toàn bộ những bản
ghi. - .reset_index(): Sắp xếp lại cột chỉ số của dataframe.
- drop:với giá trị True, nó sẽ ngăn không cho hàm reset_index tạo cột mới từ cột chỉ số của dataframe ban đầu.
Lưu dataframe về file csv
Thư viện pandas python được cho phép bạn lưu lại dataframe chỉ với một dòng code. Quá đơn thuần và giản dị phải không nào?
df.to_csv(‘comments.csv’)
Bạn hoàn toàn có thể mở file để xem kết quả lưu:

Các tham số của hàm to_csv khá tương tự với hàm read_csv. Bạn đọc hoàn toàn có thể click more thông tin khá đầy đủ của hàm này tại đây.
Tới đây mình xin kết thúc bài hướng dẫn về thư viện pandas python. Qua nội dung bài viết này, tôi tin chắc bạn đã đã có được những kiến thức và kỹ năng cần
thiết và hoàn toàn có thể làm chủ thư viện pandas trong python. Bạn cũng hoàn toàn có thể xem một ví dụ thực tiễn sử dụng thư viện này tại nội dung bài viết code thuật toán linear regression này.
Tài liệu tìm hiểu thêm
document – https://pandas.pydata.org/index.html
Bài viết gốc được đăng tại Blog thành viên của tôi.
Tải thêm tài liệu liên quan đến nội dung bài viết Hướng dẫn dùng panda meaning python
programming
python
DataFrame trong Python
 Reply
Reply 4
4 0
0 Chia sẻ
Chia sẻ
Chia Sẻ Link Download Hướng dẫn dùng panda meaning python miễn phí
Bạn vừa đọc tài liệu Với Một số hướng dẫn một cách rõ ràng hơn về Clip Hướng dẫn dùng panda meaning python tiên tiến và phát triển nhất và Chia Sẻ Link Down Hướng dẫn dùng panda meaning python Free.

Thảo Luận vướng mắc về Hướng dẫn dùng panda meaning python
Nếu sau khi đọc nội dung bài viết Hướng dẫn dùng panda meaning python vẫn chưa hiểu thì hoàn toàn có thể lại Comments ở cuối bài để Mình lý giải và hướng dẫn lại nha
#Hướng #dẫn #dùng #panda #meaning #python